
The article, Achieve enterprise integration with AWS, depicts the orchestration of Lambdas using Amazon Simple Workflow (SWF) with outstanding results. As stated, SWF requires a standalone application running in order to process the flows and this time we wanted to migrate the application to a 100% serverless solution. The article also mentions that a new service is available and looks very promising in the serverless scenario, Step Functions. Here, we want to show you how we took the previous approach and transform it into a Step Functions-led approach.
AWS Step Functions is a service that helps you to create a flow based on several units of work, often implemented in AWS Lambdas. This service is basically a state machine: given an input, an initial state will compute what’s required by the underlying implementation and will generate an output. This output serves as the input for the next state whose output might be used as an input for another step and so on until the flow is completed and the last state gets executed. Each state, or node in the visual editor in AWS Step Functions console, is implemented with a Lambda and the flow of the state machine is orchestrated by the logic specified in the transitions’ definitions.
AWS Step Functions provides the following functionality:
In IO Connect services we want to test this new feature of AWS with an enterprise integration use case based on the scenario described in the SWF implementation. We modified the file size according to the AWS Step Functions free tier for testing purposes:
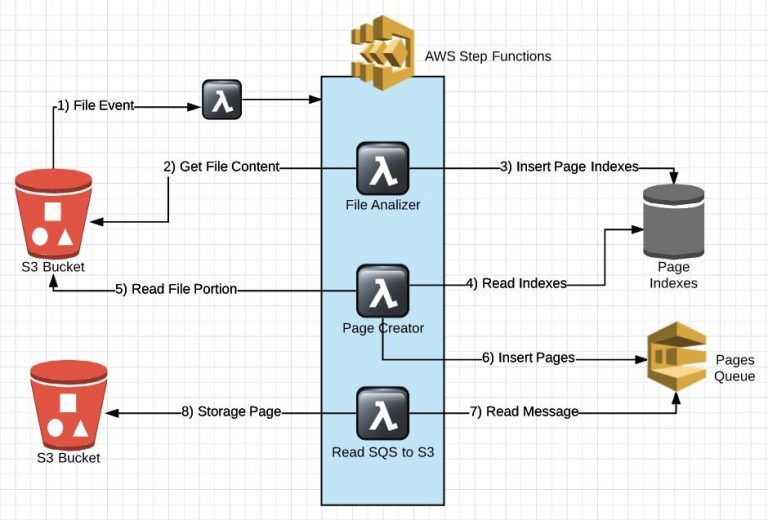
For this approach, the main idea is to use AWS Step Functions as an orchestrator in order to see all its features – logs, visual tools, easy tracking, etc. – that provides to support enterprise integration. The actual work parts are implemented using AWS Lambda. Because of the AWS Lambda limits, the units of work are very small to avoid reaching these limits, hence a good flow written in AWS Step Functions requires a series of steps perfectly orchestrated.
This was a completely new tool for us so we did some diligence to investigate about what can, can’t-do and other useful information about this tool:
Can
Can not
Consider this
For the first approach, we wanted to test how Step Functions work. For this purpose, we only set two steps in order to see what we can examine using the Step Functions logs and graph.
The StateMachine JSON
{
"StartAt": "FileIngestion",
"States": {
"FileIngestion": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:functionLambdaFileIngestion",
"Next": "Paginator"
},
"Paginator": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:functionLambdaPaginator",
"End": true
}
}
}
The Graph
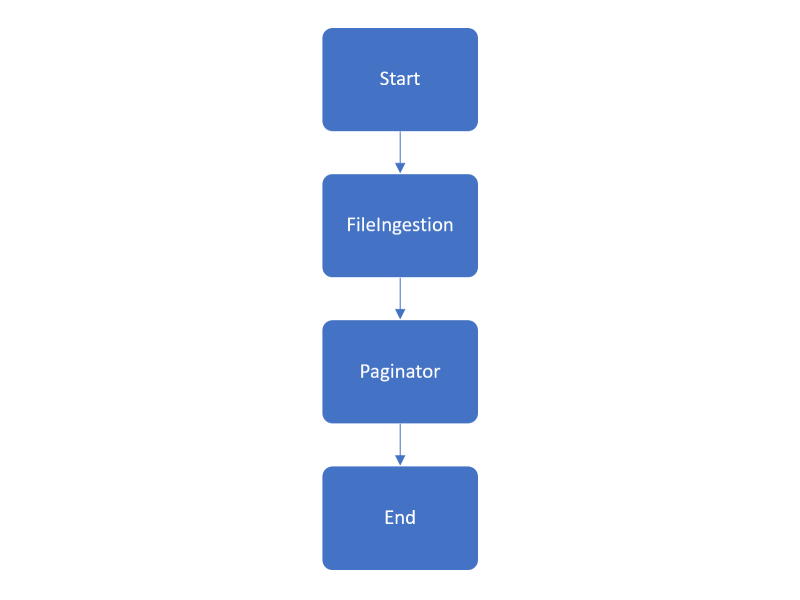
In this approach, the Lambdas have more flow control than the state machine, because one Lambda calls another and orchestrates the asynchronous executions. Also in this case, if the Lambda that writes the pages fails you can not notice it in the graph, you need to check the Lambda executions and manually identify which Lambda and why it failed.
The Metrics
Taking in count the previous implementation, We wanted to create a state machine that has more authority of the control of the flow execution. As a first step, we decided to implement a linear execution with no parallelization defined.
The StateMachine JSON
{
"StartAt": "FileAnalizer",
"States": {
"FileAnalizer": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:functionLambdaFileIngestion",
"Next": "FileChecker"
},
"FileChecker":{
"Type": "Choice",
"Choices": [
{
"Variable": "$.writeComplete",
"BooleanEquals": false,
"Next": "PageCreator"
}
],
"Default": "QueueChecker"
},
"ReadSQStoS3":{
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:functionLambdaPageWriter",
"Next": "QueueChecker"
},
"QueueChecker": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.emptyQueue",
"BooleanEquals": true,
"Next": "SuccessState"
}
],
"Default": "ReadSQStoS3"
},
"PageCreator": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:functionLambdaPaginator",
"Next": "FileChecker"
},
"SuccessState": {
"Type": "Pass",
"End": true
}
}
}The Graph

For this approach, the message channel always contains the POJO with the start and end bytes of each page.
The Metrics
We took the same state machine for the linear processing but, the Lambda resource in step ReadSQStoS3 was modified with the intention to reduce the execution time of the previous approach. I’ve added a long polling behavior in the Lambda with a maximum of 10 messages, with this, the Lambda waits for a maximum of 10 messages in SQS if available (if 20 seconds pass and the 10 messages are not visible, it gets the maximum available at that moment) in the queue, get them and calls another Lambda asynchronously to write these 10 messages.
The Metrics
For this implementation, we added a series of 5 branches in order to read the first and end byte of each page and send a message to SQS with the page content in parallel.
Here we faced two problems:
The StateMachine JSON
{
"StartAt": "FileAnalizer",
"States": {
"FileAnalizer": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:LambdaFileIngestion",
"Next": "FileChecker"
},
"FileChecker":{
"Type": "Choice",
"Choices": [
{
"Variable": "$.writeComplete",
"BooleanEquals": false,
"Next": "ParallelWritePage"
}
],
"Default": "QueueChecker"
},
"ParallelWritePage":{
"Type": "Parallel",
"Next": "DeleteRead",
"Branches": [
{
"StartAt": "SetBatchIndex0",
"States": {
"SetBatchIndex0": {
"Type": "Pass",
"Result": 0,
"Next": "PageCreator0"
},
"PageCreator0": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:LambdaPaginator",
"End": true
}
}
},
{
"StartAt": "SetBatchIndex1",
"States": {
"SetBatchIndex1": {
"Type": "Pass",
"Result": 1,
"Next": "PageCreator1"
},
"PageCreator1": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:LambdaPaginator",
"End": true
}
}
},
{
"StartAt": "SetBatchIndex2",
"States": {
"SetBatchIndex2": {
"Type": "Pass",
"Result": 2,
"Next": "PageCreator2"
},
"PageCreator2": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:LambdaPaginator",
"End": true
}
}
},
{
"StartAt": "SetBatchIndex3",
"States": {
"SetBatchIndex3": {
"Type": "Pass",
"Result": 3,
"Next": "PageCreator3"
},
"PageCreator3": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:LambdaPaginator",
"End": true
}
}
},
{
"StartAt": "SetBatchIndex4",
"States": {
"SetBatchIndex4": {
"Type": "Pass",
"Result": 4,
"Next": "PageCreator4"
},
"PageCreator4": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:LambdaPaginator",
"End": true
}
}
}
]
},
"DeleteRead":{
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:LambdaGetLastIndex",
"Next": "FileChecker"
},
"ReadSQStoS3":{
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:LambdaPageWriter",
"Next": "QueueChecker"
},
"QueueChecker": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.emptyQueue",
"BooleanEquals": true,
"Next": "SuccessState"
}
],
"Default": "ReadSQStoS3"
},
"SuccessState": {
"Type": "Pass",
"End": true
}
}
}The Graph
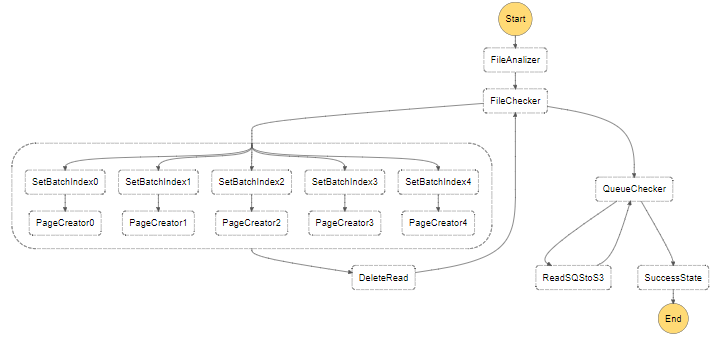
The Metrics
AWS Step Functions is a tool that allows you to create and manage orchestrate flows based on small units of work. The simplicity of the language makes it perfect for quick implementations, as long as you already have the units of work identified.
Unfortunately, as this is fairly new service in the AWS ecosystem, functionality is severely limited. A proof of this is the fact that you need to maintain a fixed number of parallel steps and if you end up having less work than parallel steps you must add control logic to avoid unexpected errors.
Moreover, given the limits found in AWS Lambda and Step Functions, computing of high workloads of information can be very difficult if you don’t give a good thought to your design to decompose the processing. We highly recommend you give a read to our blog Microflows to have an understanding of what this means.
On the plus side. if you want to transport small portions of data or compute small processes in a serverless fashion, Step Functions is a good tool for it.
In the future, we will evaluate a combination of other new AWS services like AWS Glue and AWS Batch together with Step Functions to achieve outstanding big data processing and enterprise integration.
Thanks for taking time to read this post. I hope this is helpful to you at the moment you decide to use Step Functions and do not hesitate to drop a comment if you have any question.



